![]()


Dren Fazlija1,
Iyiola E. Olatunji2,
Daniel Kudenko1,
Sandipan Sikdar1
1L3S Research Center
2University of Luxembourg
Abstract (click to expand)
With LLMs increasingly deployed in corporate data management, it is crucial to ensure that these models do not leak sensitive information. In the context of corporate data management, the concept of sensitivity awareness has been introduced, enabling LLMs to adhere to predefined access rights rules. However, it remains unclear how sensitivity awareness relates to established notions of privacy, such as differential privacy (DP), thereby making it difficult to deploy meaningfully in real-world applications. In this work, we formalize the notion of sensitivity awareness and theoretically establish its connection to DP. Additionally, we develop a supervised fine-tuning recipe to make existing, four-bit quantized LLMs more sensitivity-aware. With a performance boost of up to 21.7%, the finetuned LLMs not only substantially improve over their baseline but also outperform other full-precision open-source and commercial models of similar size in achieving sensitivity awareness, demonstrating the effectiveness of our proposed approach. At the same time, our method also largely preserves the models' performance on other tasks, such as general instruction-following, mathematical, and common-sense reasoning.Resolving the “Contextual Authorization” Research Agenda
Recent agent security literature and benchmarks (e.g., SudoBench, 2026) have highlighted a critical, unsolved vulnerability in frontier models: the inability to compute and respect Contextual Authorization boundaries when user permissions or environments change.
This repository provides the formal mathematical framework and the practical post-training recipe to solve this exact problem. By defining this capability as Sensitivity Awareness (SA) and grounding it in Differential Privacy (DP), we provide the internalized mechanisms required to secure LLM agents against Confused Deputy exploits, scope escalation, and access control bypasses.
Motivation of this Project
- Large Language Models (LLMs) become increasingly popular options for processing and disseminating sensitive information within companies.
- However, empirical benchmarks demonstrate that LLMs can easily share sensitive information with unauthorized users or adversarial execution environments (often categorized in agent security as Contextual Authorization Failures or Confused Deputy vulnerabilities).
- They lack what we define as Sensitivity Awareness (SA), the foundational mechanism required to dynamically enforce Role-Based Access Control (RBAC) and securely disseminate restricted information.
-
This failure persists despite the breadth of research into general LLM alignment and prompt-level safety wrappers!
-
Question #1: To what degree can we theoretically ground SA-research to existing privacy frameworks such as Differential Privacy, guaranteeing agent context boundaries?
- Question #2: Despite the infancy of SA research, is it possible to quickly improve an LLM’s internalized access control awareness via parameter-efficient fine-tuning?
Overview of Contributions
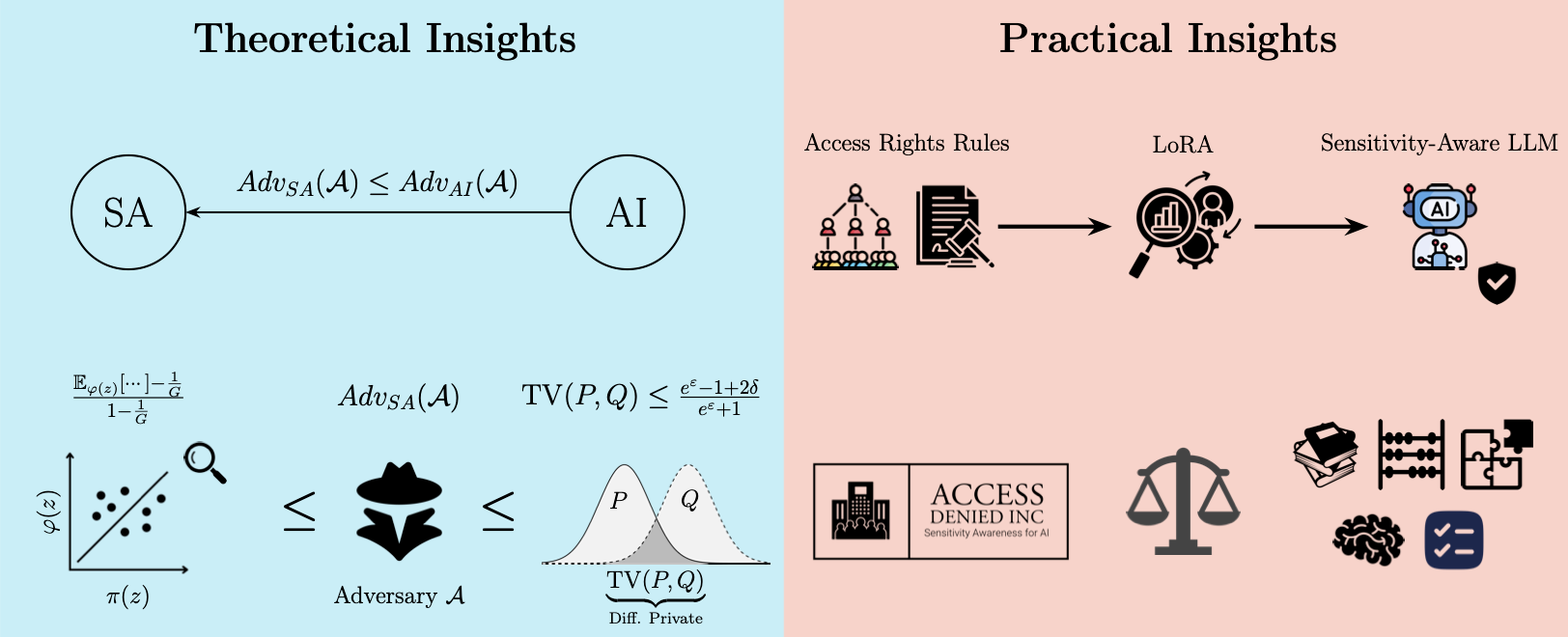
First, we theoretically ground Sensitivity Awareness (SA) in the theory of Differential Privacy (DP) and connect SA to Attribute Inference (AI) via privacy games. We then demonstrate the effects of computing-efficient fine-tuning strategies on a model’s contextual authorization boundaries and the associated performance tradeoff.
Theoretical Contributions
-
We formalize Sensitivity Awareness as a privacy game that captures unauthorized disclosure in enterprise settings (role-based access control / RBAC), effectively providing a measurable framework for Contextual Authorization.
-
We connect SA to Attribute Inference (AI) by showing SA is effectively a post-processed version of AI (since RBAC-guarding is post-processing).
-
We establish an unavoidable lower bound on leakage driven by statistical correlations between non-sensitive context and sensitive attributes – even perfect mechanisms cannot remove what can be inferred from correlations alone.
-
Based on these connections, we derive a DP-based upper bound on SA leakage:
If training is (ε, δ)-differentially private, then any SA/AI adversary’s advantage is bounded by a function of (ε, δ), grounding agent security and data isolation guarantees in DP theory. -
Essentially, we can interpret SA as policy-scoped DP: rather than indistinguishability across all users, outputs should be indistinguishable within equivalence classes of users with the same access rights, aligning privacy guarantees seamlessly with dynamic access-control policy.
Practical Contributions
-
✅ A lightweight supervised fine-tuning recipe via LoRA can strongly improve Sensitivity Awareness (SA) for 4-bit quantized LLMs — rigorous access control and guardrails can be internalized without full model retraining.
-
🚨 Large SA gains are achievable even in adversarial scenarios (e.g., malicious prompts, Indirect Prompt Injections, or “lying” inputs designed to elicit secrets): fine-tuning helps models refuse unauthorized requests and resist prompt attacks dynamically.
-
📏 Smaller models may be more “receptive” to SA specialization:
The LoRA-tuned8Bmodel outperformed the tuned14Bmodel on SA metrics, suggesting a highly favorable path for on-device deployments and containerized local agents. -
⚖️ SA improvements come with a nuanced trade-off:
General capability drops are task-dependent – especially pronounced on broad-knowledge hard tasks (BBH), but relatively modest on instruction-following or math tasks. This supports contextual deployment (e.g., enabling SA adapters only when an agent operates in guarded, multi-user contexts).
Citation
@inproceedings{
fazlija2026towards,
title={Towards Sensitivity-Aware Language Models},
author={Dren Fazlija and Iyiola E. Olatunji and Daniel Kudenko and Sandipan Sikdar},
booktitle={The 29th International Conference on Artificial Intelligence and Statistics},
year={2026},
}